File Juicer for macOS
Text, Images and Images of Text
If the PDF contains images it will extract them. If it contains text it will extract text. This sounds simple, but when a text document is scanned, text is becomes images. A scanner actually takes a high quality photo of the document.
To turn images into text you need Optical Character Recognition software, which will take a while to learn to use efficiently.
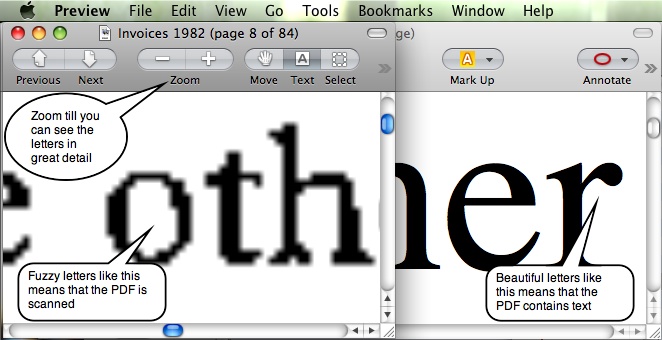
Is It Scanned?
This is easy to check. Drop the PDF into Preview and zoom in to see the detail of letters.